To add to the complexity of generating stats, how do you get stat events from a DataCenter (DC) in Singapore, a DC in Western Europe, a DC in Oregon to a database for querying in West Virginia - near real-time? I used multisource replication, and the BLACKHOLE storage-engine to do so with MariaDB.
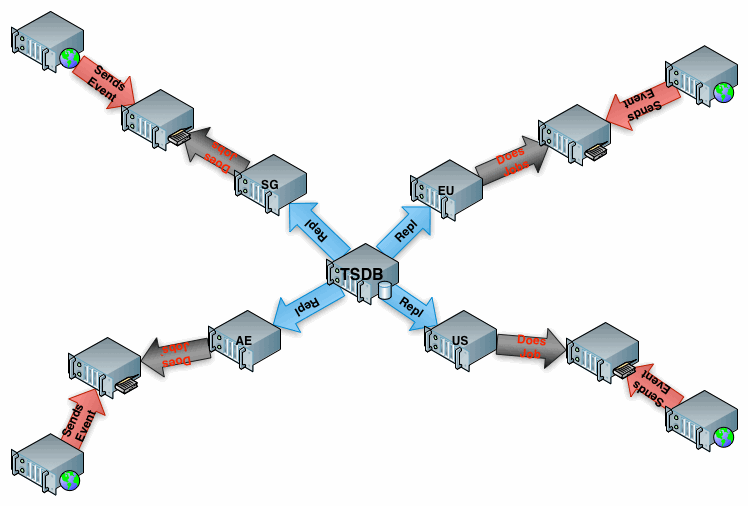
Above is an image that shows a Webserver in some part of the world sends Events for tracking various interrupts to a BeanstalkD queue at time T in the same region. Each Region has a set of Python workers that grab events from BeanStalkD and writes the event to a local DB. Then the TSDB Database, a MariaDB 10.0.4 instance, replicates from each BlackHole StorageEngine BeanStalkD Worker server.
The obvious question might be why not use OpenTSDB? The TSDB daemon couldn't handle the onslaught of stats/second. The current HBase TSDB structure is much larger compared to a compressed INNODB row for the same stat. Additionally a region may loose connectivity to another region for some time so I would need to queue in some form or another events until the network was available again. Thus the need for a home grown solution. Now back to my solution.
The Structure for the event has the following DDL.
Currently we are using 32 shards defined by each bigdata_# database. This allows us to scale per database and our capacity plan is not DISK IO but based on diskspace.
MariaDB [(none)]> show databases; +--------------------+ | Database | +--------------------+ | bigdata_0 | | bigdata_1 | | bigdata_10 | | bigdata_11 | | bigdata_12 | | bigdata_13 | | bigdata_14 | | bigdata_15 | | bigdata_16 | | bigdata_17 | | bigdata_18 | | bigdata_19 | | bigdata_2 | | bigdata_20 | | bigdata_21 | | bigdata_22 | | bigdata_23 | | bigdata_24 | | bigdata_25 | | bigdata_26 | | bigdata_27 | | bigdata_28 | | bigdata_29 | | bigdata_3 | | bigdata_30 | | bigdata_31 | | bigdata_4 | | bigdata_5 | | bigdata_6 | | bigdata_7 | | bigdata_8 | | bigdata_9 | | information_schema | | mysql | | performance_schema | +--------------------+ 35 rows in set (0.16 sec)
The database bigdata_0 is the only database that is slightly different than the rest. It has a table defined as EventTags that is not in the rest of the databases. EventTags is the map of eventId to tagName where eventId is just a numerical representation of a part of the md5 of the tagName. Each numerical representation falls into an address space that denotes the range of which database a tag should belong to. We use the EventTags table for the front-end to search for a stat to plot on a graph.
CREATE TABLE `EventTags` ( `eventId` bigint(20) unsigned NOT NULL DEFAULT '0', `tagName` varchar(255) NOT NULL DEFAULT '', `popularity` bigint(20) unsigned NOT NULL DEFAULT '0', `modifiedDate` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`eventId`,`tagName`(25)), KEY `eventTag` (`tagName`(25)) ) ENGINE=BLACKHOLE DEFAULT CHARSET=utf8
EventDay contains the actual value of the stat combined for the last 1 minute (currently). Our granularity allows down to a second but we found seeing events for the last minute is fine. The SQL produced for events are the following.
CREATE TABLE `EventDay` ( `eventId` bigint(20) unsigned NOT NULL, `createDate` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT 'min Blocks', `count` bigint(20) unsigned NOT NULL DEFAULT '0', PRIMARY KEY (`eventId`,`createDate`) ) ENGINE=BLACKHOLE DEFAULT CHARSET=utf8
MariaDB's multi-source replication then downloads the statement based binary logs from each of the workers in some part of the world and applies the SQL to a combined database that represents all regions. Note that the central database is of the same Structure BUT now the engine is Compressed INNODB with KEY BLOCK SIZE set to 8.
The front-end sits on top of the central database and we record everything from a single item being sold to load on our auto-scaling web-farm. Which allows us to do some interesting plots like Items sold as a function of Load over time. I(L(t))
Currently with this method we are producing 60K events a second that translates to a few thousand database updates a second across 4 replication threads (8 threads total). Keeping all data up to date from within the last minute near realtime.
No comments:
Post a Comment