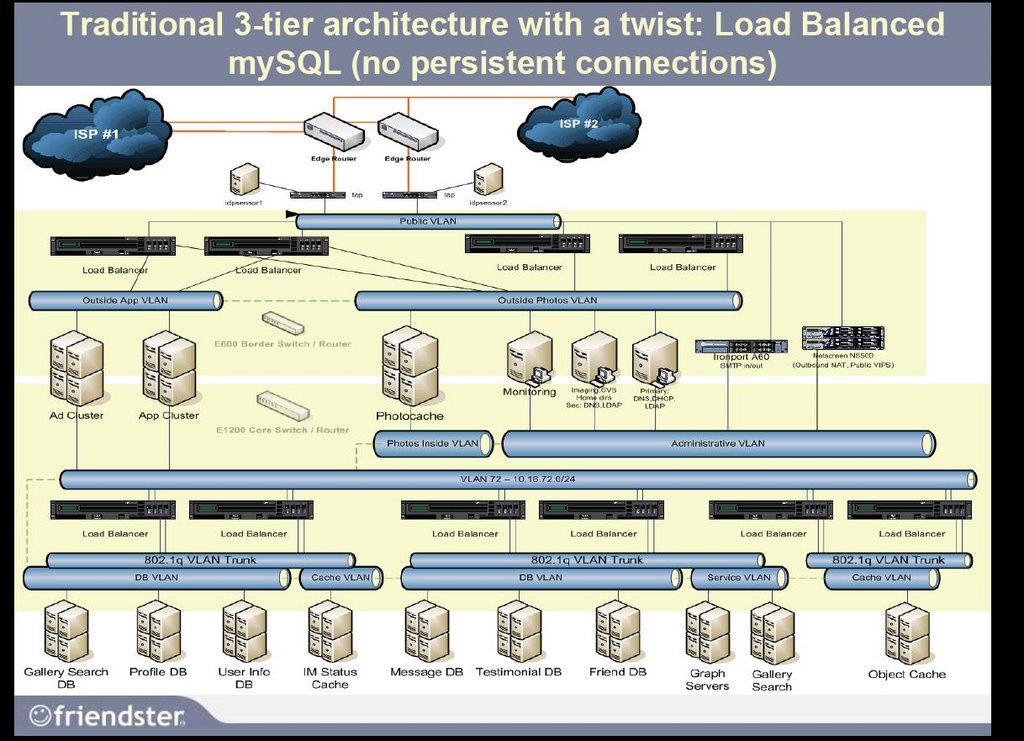
Above is a diagram of the Friendster backend at the time I was there. The entire presentation can be found here at mysqluc.com. Due to all the turmoil at Friendster, even with the coolest and most competent VP of Engineering in the business Jeff Winner we could not push my intended design. This design is now used at Flickr with huge success.
What I wanted to do was introduce a system that allowed Friendster to partition the user data. This was the same system that I started to implement at AuctionWatch in 1999 and was not able to complete.
Each 64bit AMD server would house 500K distinct users and all their data. I provided a system to increase capacity, scale linearly on a fraction of the servers, at the fraction of the cost. There would be no need to cache any data, and everything could be fetched real time. In fact when I was discussing this with Jeff who loved the idea and saw the potential in walks Kent the CFO (now the 5th CEO) and sees 500K users on the white board. So, Kent goes hey what's a Sook user? We all chuckled and that became the project name, project 500k.
Now here was my argument. What Friendster was using was simple old replication. Replication is a batch oriented system, when SQL is applied on the master it's logged to a file, slaves then read that file (think of tailf) then takes the SQL that is written and applies that same SQL on a slave server. When the application runs out of read capacity, the solution is to add more slave servers. In this model there is an inherent limitation. Below is a list of some:
- There is a single point of failure on the master
- ALL write SQL operation done to the master must be replicated to the slaves
- When IO bandwidth is low replication lags, causing slave lag
Now many people to get around these issues build other masters to take over or come up with clever tricks in the application to get around these problems.
I wanted to solve the issue without a trick. What was very expensive for Friendster was the user generated data. There was a crap load of it, about 500GB of it at the time. Replicating all that data was the cause of my heart-ache. Since the application was very dynamic and required huge ranges, I/O bandwidth was cut on every range query causing replication lag.
Project S00k solved these issues.
- Here was the argument:
- Split up user data
With a small amount of data web developers can do full table scans at a fast rate with a high concurrency if the data is small enough. So, bad code could go out and not take down the site.
On top of that, instead of replicating to an INNODB datafile that is 500GB that is very expensive to support by having multiple copies of, let’s only deal with a datafile or database size that is a few gigs in size.
Why is this better?
- The data is faster to backup
- The data is faster to recover
- The data can fit into memory
- The data is easier to manage
Splitting up the user data so that User A exists on one server while User B exists on another server, each server now holds a shard of the data in this federated model.
- Provide High Availability
A problem at Friendster was if the master goes down, the site goes down. To solve this:Take each S00K Shard and put it in a replication ring. This is now a backup of the Shard of data. If one server out of the Shard pair goes down so what keep writing to the other. If both go down only a small amount of users are affected, show them the outage notification while other users are still able to use the site.
In single-master many-slave architecture write bandwidth is throttled, in federation you can write to all the masters and read from them.
Replication is a batch system it’s IMHO designed for backup of the database. Each server of the shard replicates it’s data to it’s pair. To remove effects of replication lag, stick the shard viewer to a single server in the ring. All operations are done there. So, if there is replication lag, or replication is broken users would not notice. Read and write to the same place.
But, because of the environment in Friendster getting this done was not possible. So, I worked on the same old system and we where never able to solve the root of the capacity issues.
Next: Flickr 5 min talk about this design and we start to work on implementing it.
13 comments:
Interesting.
I understand Livejournal split their users into different clusters of machines and that the biggest problem with this is bringing data together from the separate machines for the "friends" page (which contains entries from several users).
How does your design cope with queries that need info from more than one shard?
Tom
LJ split their of data by user so that my user lives on a different partition than yours, but this scheme has partitioned it by type. Therefore, all users are in one scheme, messages, photos, testimonials in another.
Thus bringing data together isn't a problem unless you're displaying different types of data, in which case I think it's relatively cheap to issue the appropriate query for each type & then sort them all together on the application side.
For our solution it made much more sense to use replication. Over 80% of our queries where READs we wrote our statistics (page views, etc) to a totally different machine. So replicating data that isn't updated often is a solid solution.
Chris - my two cents
@ chris:
What happens when your data consumes 800 GB of space?
Would you replicate your data to many slaves?
1TB slaves costs a lot of money and at best you can get maybe 1% of the data in memory.
If the application hardly writes, will always stay small then replication is good enough.
Interesting read.
I've done some sharding of data across machines, but it was in a search engine and the storage engine was designed from scratch around it, so it was pretty easy to implement. And it could scale on cheap machines with small disks to huge capacities. This is maybe the best way to scale with cost in mind.
I'm now thinking of splitting MySQL data across machines for another project, and one question comes to mind:
Splitting by one table (users in this case) is obvious. But what about sharding on more than one axis? Suppose I have another huge table that I want to split, and it has to join with the users table. Off the top of my head, this sounds like it would make queries much much more complicated and make a whole mess out of the design. But I haven't really given it much thought yet.
Have you done anything like that? What ae your thoughts?
very interesting, but one question.
suppose now I have 10 mysql backends, i split my users to them. one year later, we should add 10 more backends, how could I split the old data on the previous 10 backends to the new 20 backends?
Louis
Hmm... Quite an interesting read.
Very interesting post, I have to admit I am a little confused as to how you create data for a whole bunch of different users though. Like on a users friends page.
"Splitting by one table (users in this case) is obvious. But what about sharding on more than one axis? Suppose I have another huge table that I want to split, and it has to join with the users table."
My guess is that this is why denormalization is mentioned prominently as one of the features of sharding -- you'd be merging those giant tables into one ginormous table, and then sharding it. You would have some considerable data redundancy in such a system, and you'd probably have to move relationship checking to code, not relations.
RE:"Splitting by one table (users in this case) is obvious. But what about sharding on more than one axis? Suppose I have another huge table that I want to split, and it has to join with the users table."
What you are speaking to isn't necessarily a shard, but where you will get some real performance increase is when you split a table with many columns into two: one with the data that you query often, and the other with data that you don't. This will reduce the overall row size, thus faster to scan, sort, join or whatever. Along with selectively de-normalizing your data, this can make a big difference.
Interesting post the biggest problem with LJ is the friend page isnt it?
---------------------------
Interior Designs Scotland
Still no response for the issue that requires queries across multiple shards?
BTW, nice article, but your failure to utilize commas correctly forced me to read many sentences more than once to infer proper meaning. I suggest either getting an editor or reading this book:
http://www.amazon.com/Eats-Shoots-Leaves-Tolerance-Punctuation/dp/1592400876
Web Art Sense a web design company is here for a purpose to make art and design of your imagination alive and real on the web platform. After several months of hunting of the best talent and struggling for the name of their design company they finally reached a vertical which engages their vision of togetherness. The best talented people in web designs have joined hands to compete and provide innovative, unique concepts to users/clients all across the globe. Web Art Sense is not any design company; they take real care of having your brands be presented that invokes your revelation to others who see it.
Web Art Sense has their sales offices in London, New Jersey and New Delhi are heading towards marketing themselves to main continents of Europe, Australia and America. Web art sense already has ground foundation and is providing web based design development and SEO Services in countries like USA, UK, Australia and Italy. Web Art Sense has been growing above hundred percent every financial year since its foundation.
Web Design Company
Web Art Sense a leading web design company, affordable web design, web development, ecommerce, XHTML services. Web Design Company offers a complete collection of web design solutions for business. Web Art Sense team of professionals with proven knowledge in the field of web design & development are skilled of providing high quality, e commerce websites, development and website redesign & maintenance solutions.
Post a Comment